如何看待开源模型DeepSeek综合性能吊打Openai?。
这个模型不简单,自从上个月发布之后,一天时间霸榜开源模型,并在性能上OpenAI的GPT-4o不分伯仲,甚至是吊打
DeepSeek模型到底是什么?
这是一家来自家中国杭州的公司Deepseek,Deepseek的中文名是“深度求索”,为量化巨头幻方量化的子公司。12月26日发布的开源大模型:DeepSeek-V3的开源AI模型。其具备6710亿参数,激活参数达370亿,在14.8万亿token上完成预训练,它的多项性能指标对齐海外顶尖模型。
就连在硅谷,DeepSeek-v3墨西哥则被称作“来自东方的神秘力量”。
DeepSeek-V3的性能表现
看下面的图我们就知道
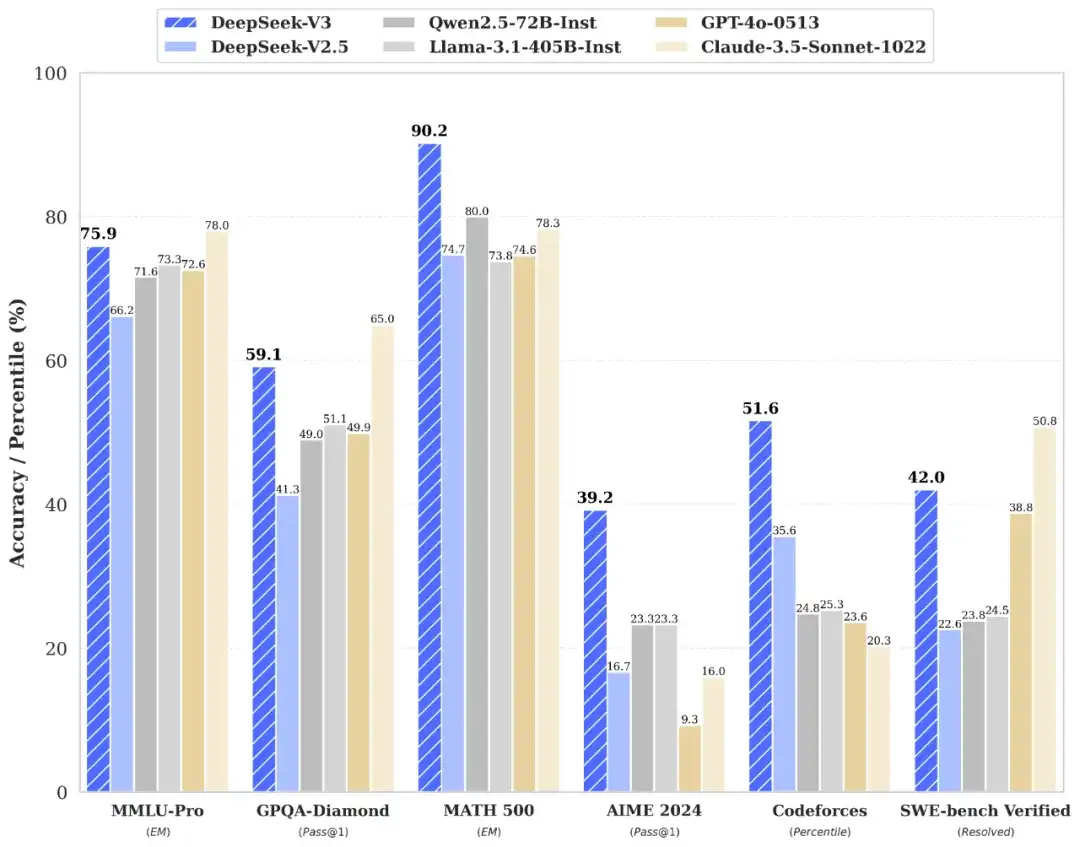
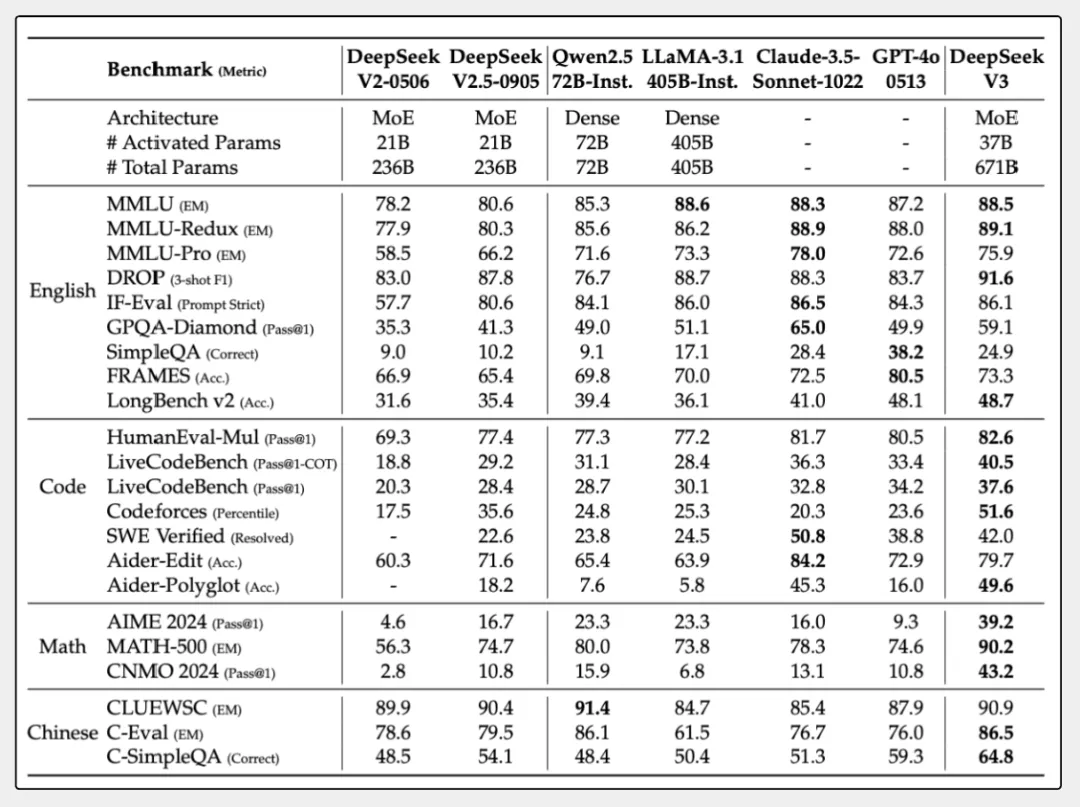
在将其与Qwen2.5-72B、 Llama-3.1-405B,GPT-4o 以及 Claude-3.5-Sonnet等其他开源模型进行对比, DeepSeek-V3综合性能完爆其他大模型
新模型DeepSeek-V3拥有 6710 亿个参数,并且采用了 MOE(混合专家)架构。
这是什么概念?
我们都知道,这些参数决定了AI模型在训练过程中如何学习和适应输入数据,从而影响模型的预测性能。这个解释不太好理解。参数数量越多,模型越复杂,那么就说明它的表达能力和更潜在性能就越强!
它还采用的MOE架构,可以根据输入的Promt来进行激活需要的特定的参数,每次处理一个单词都会利用算法进行特定筛选和激活370个370 亿参数,这样效率高就不奇怪了
话说回来MOE架构是什么呢?
说起MoE大模型,他说基于分治思想的深度学习模型。MoE架构分为两部分:专家(Experts),可以说是每个专家都是一个神经网络。另外一部分是路由。顾名思义,决定了每个token交给哪个专家来处理。
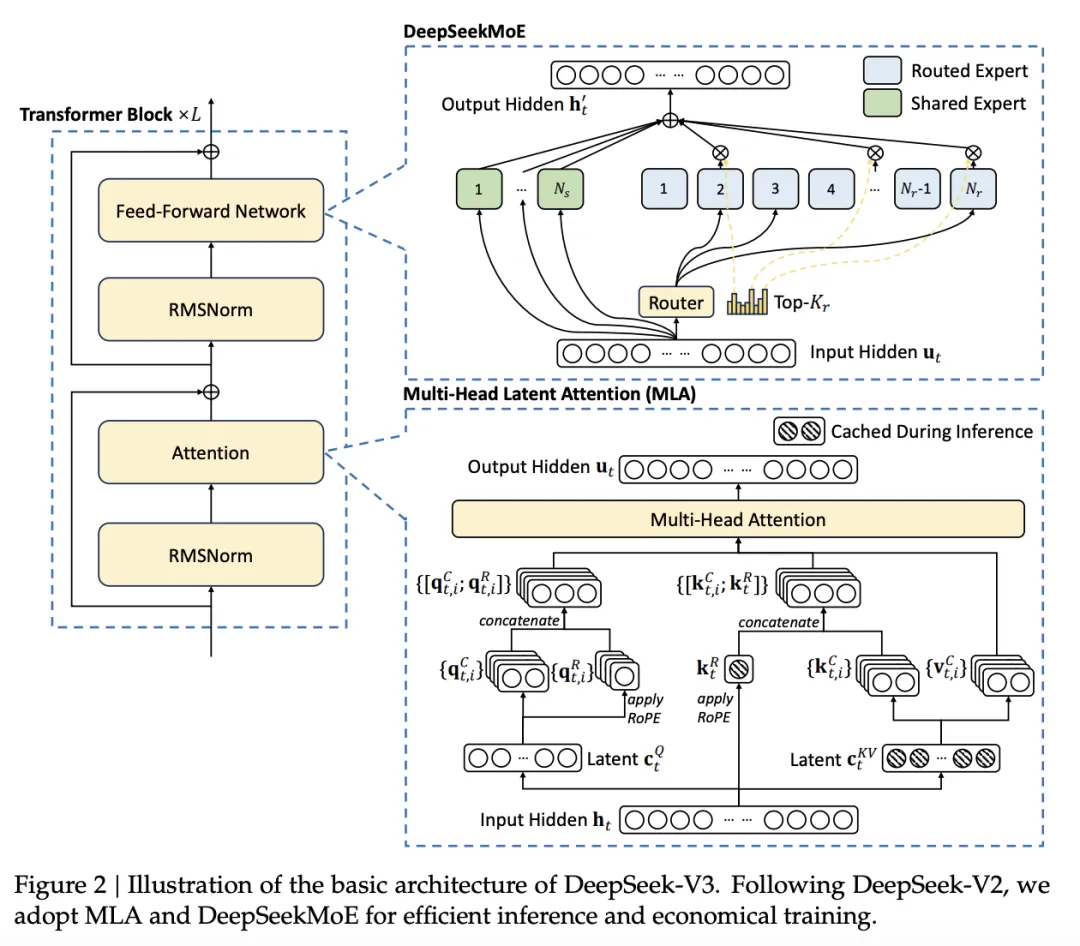
在AI大模型中,它将整个模型划分为多个子模型,每个子模型负责处理一部分任务。在推理时,根据输入数据的特性,选择最合适的子模型进行处理。
比如如果你要把一个2T数量的token的1.3B参数模型替换为MOE架构,相同的性能,训练可以从原来的2.4T的数据减少到0.4T的数据量。
同样的智能水平,MoE模型架构训练可以更少量的计算量和内存需求,这也是未来大模型的趋势。
更值得一提的是,MoE模型还可以轻松扩展到成百上千个专家,使得模型容量极大增加,同时也允许在大型分布式系统上进行并行计算。前不久,昆仑万维宣布开源2千亿参数的Skywork-MoE。而在此之前,浪潮信息的源2.0-M32、Qwen1.5-MoE-A2.7B 等,也都纷纷开源。
所以不得不承认,MoE大模型作为当前AI领域的技术热点,同是也是大模型必备的底层架构之一。如果你想了解更多关于LLM的底层知识,正好可以来学习一下知学堂的《AI大模型进阶之旅》直播课,有业界的大佬进行教课,从0到1拆解DeepSeek-V3底层的MoE工作原理以及实现方式,带你全程体验微调过程。从理论到实践,深度讲解大模型的模型架构,从而对MoE的具体应用以及基于深度学习的LLM有一个更加深入细致的理解,直通车我放到下方了,大家直接领取就行:
很多同学上完课程基本不上都真正学到了AI大模型的核心,训练了自己的大模型智能体,这对于快速入门大模型,是非常值得去学习的。
除了延续基础的MOE架构之外,DeepSeek-V3还引入了其他两个技术创新:
零损失的负载均衡策略:
DeepSeek-V3这个策略模式,可以自我动态监控,从而达到一个均衡的工作负载,让它们运行,对于其他模块来说,基本上是不影响的。
多单词预测
顾名思义,就是能同时预测多个未来单词,保证生成内容时,能够节约一部分输出时效。
单单这个这个多词元预测,就能让DeepSeek-V3 模型,在生成效率上提升3个层次,从原来的20 TPS 大幅提高至 60 TPS,单秒可能生成 60 个 token的数量
DeepSeek-V3推理能力到底有多强?
在数学上,在美国数学竞赛(AIME 2024, MATH)和全国高中数学联赛上,DeepSeek-V3 大幅超过了所有开源闭源模型。
在编程方面
DeepSeek-V3的通过率达到了将近40%,领先于Llama 3.1的31%和Claude 3.5 Sonnet的33%。在HumanEval-Mul测试中,DeepSeek-V3得了83%,比Qwen 2.5的78%高,并且和GPT-4o的80.5%差不多。
在多语言和非英语任务上
在中文多语言理解)测试中,DeepSeek-V3得了89分,领先于Llama 3的74分。
总的来说,DeepSeek-V3成绩已经可以媲美一些主流的闭源大模型了
关键是训练成本还很低!DeepSeek-V3的训练成本只有557万美元,如果对于要训练业界主流大模型的Meta的Llama 3.1来说需要5亿美元,而DeepSeek-V3知识冰山一角。
至于为什么要开源
我想着是DeepSeek力求在通往 AGI 的道路上不断前进的一个明智之举。国外既有闭源模型,也有开源模型。
DeepSeek的开源,尤其是对开发者更加友好,喜欢自己部署和训练llm的开发者们自己可以在本地搭建环境,训练、微调、部署、应用,这也是未来独立开发者的必经之路。
毕竟AI大模型正是当下的技术风口。传统的开发者们如果智慧CRUD,那么基本上会被AI程序员如Delvin或者AI全栈开发者所取代,未来的程序员一定是利用大模型相辅相成的,成为大模型全栈工程师是必经之路。如果你自学感觉很费劲的,这个「AI大模型进阶训练营」很值得你去学习,除了AI 底层原理分析和前沿技术解读,还有一些商业化项目落地拆分,还有50套可以直接应用到自己项目中的demo供大家来使用。从0到1教会你训练,部署,和应用,这对于真正掌握技术和提升个人竞争力非常有用,入口我放到下面了↓

课程中会教会你利用LangChain+Fine-tune定制个人的LLM应用、打造自己的AI Agent,这些是真正能帮助我们AI潮流下的大模型技术能力,很多人都学习完这个转向了AI全栈程序员,薪资都翻了两倍。
不管怎么样,DeepSeek大模型对于成本,架构和训练数据都做到了最简,最优和最低。这回国内的大模型又扳回了一局。DeepSeek-V3大模型不得不说一突破了大模型新的高度,难怪被业界成为国产之光,看来国内的大模型快要崛起了
可见,现在这个时刻来到AI了
本文转载于MSN,文章来源于知乎作者:互联网科技小于哥,文中观点仅代表作者本人,本站仅供信息存储