为什么deepseek的回答里会说自己必须要符合openAI的政策?。
套个公式:DeepSeek 可能蒸馏了 ChatGPT 的数据,但 DeepSeek 套壳 ChatGPT 不太可能。
大模型混淆自我身份认知无非几种可能,一是直接 API 套壳,二是训练中蒸馏模型或利用了其他模型输出的合成数据,三是角色扮演,四是模型幻觉说错了,因为有时也未必故意蒸数据,现在互联网抓取的合成数据很多,可能是混杂的数据没清洗干净。
前段时间有一篇论文[1],研究大语言模型的蒸馏量化。从论文中的结论来看,除了 Claude 和豆包,其他各家多少都蒸馏了模型数据:
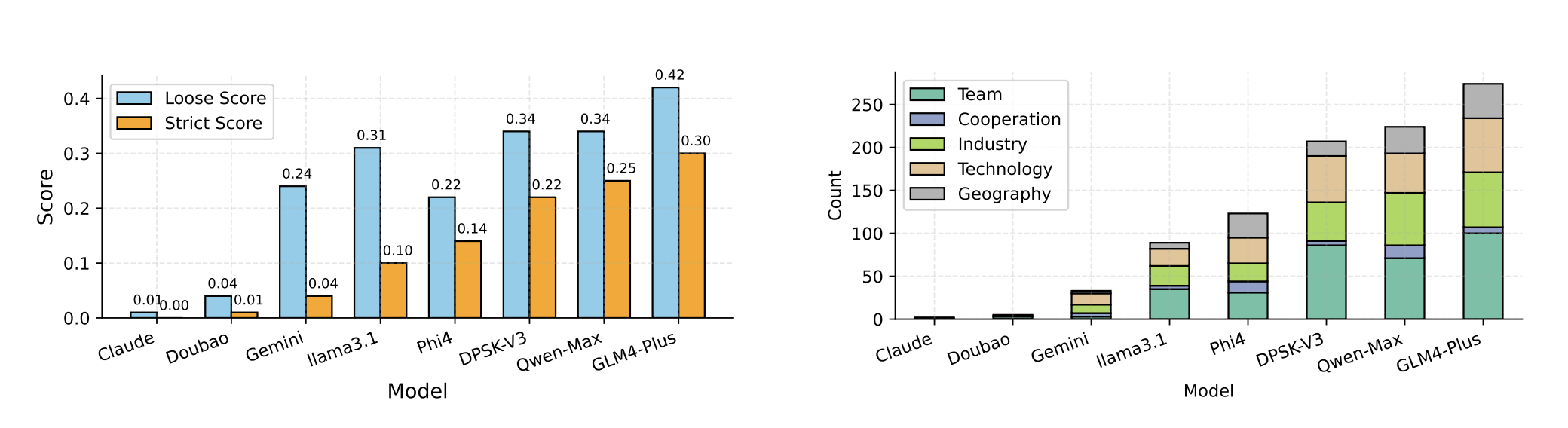
豆包发布 1.5 Pro 还专门强调了自己「不使用任何其他模型的蒸馏数据,确保数据来源的独立性和可靠性。」
Sam Altman 之前也阴阳说「复制一些已有的工作相对容易」[2],被很多人解读为是在批评 DeepSeek,也有很多人猜测

但是我个人还是支持 DeepSeek,原因有二,其一是 DeepSeek 开源,且在 AI Infra 和算法上有所创新,属于是在帮 OpenAI 体面;其二是蒸馏模型、合成数据会使模型性能下降,而 DeepSeek R1 表现足够惊艳。
比如有一个新的测试集,叫做人类最后的考试(HLE):
HLE 包含 3000 道题目,涉及数学、人文学科和自然科学等多个领域,是由全球各学科专家共同开发的,题目包括适合自动评分的选择题和简答题。该测试集处于人类知识的最前沿,旨在成为该类型的最终封闭式学术基准,并且覆盖广泛的学科领域。
在这个测试集上,GPT-4o 和 Claude 3.5 Sonnet 分别获得了 3.3% 和 4.3% 的正确率;而 o1 和 DeepSeek-R1 获得了 9.1% 和 9.4% 的正确率(R1 是文本模型,所以没有测试多模态题目):

但依然可以看出,R1 的能力是能持平甚至略优于 o1 的,所以 R1 即便蒸馏了一些 o1 的数据,也肯定有自己的数据和方法。
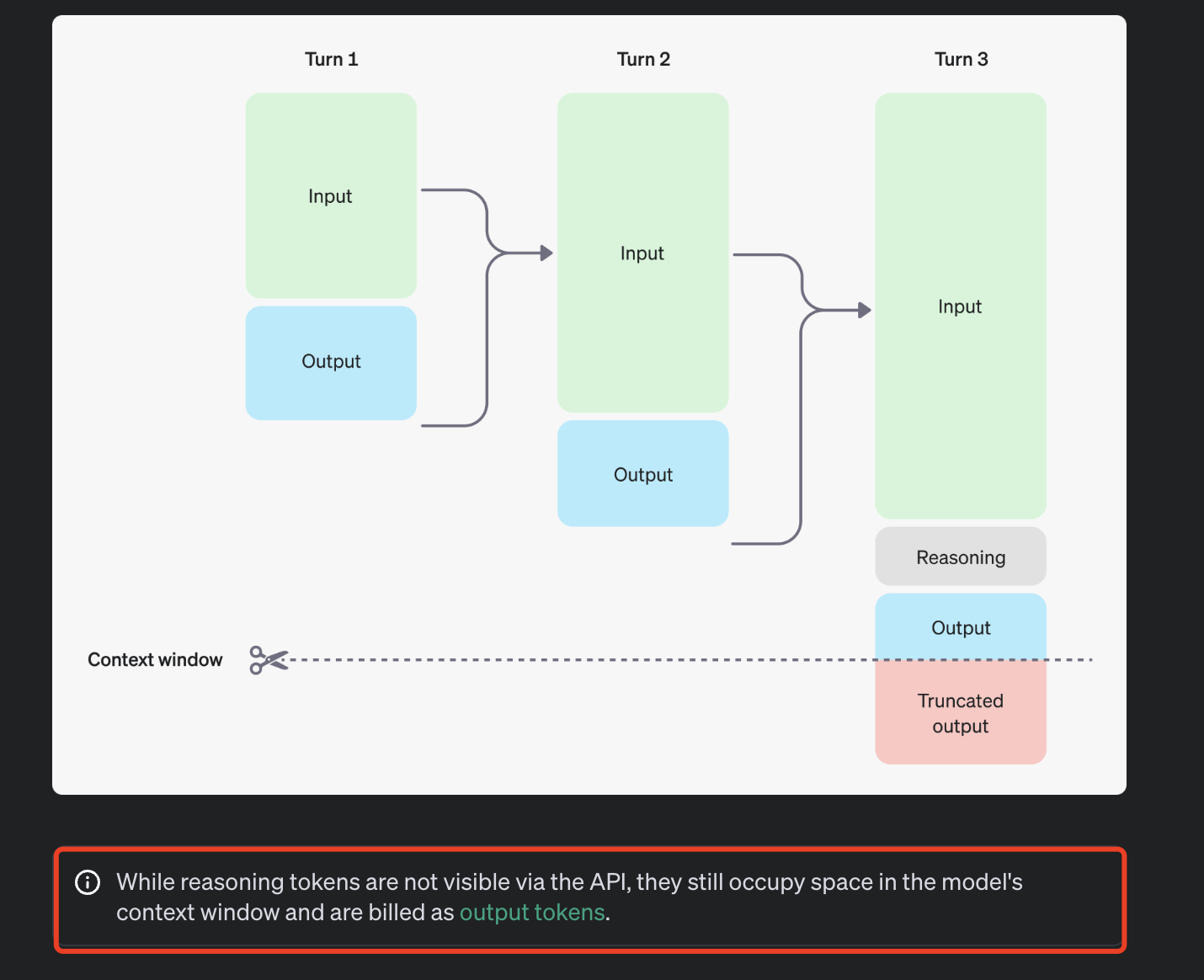
更何况,OpenAI o1 是隐藏自己 CoT 过程的,API 中的只计费,不可见:
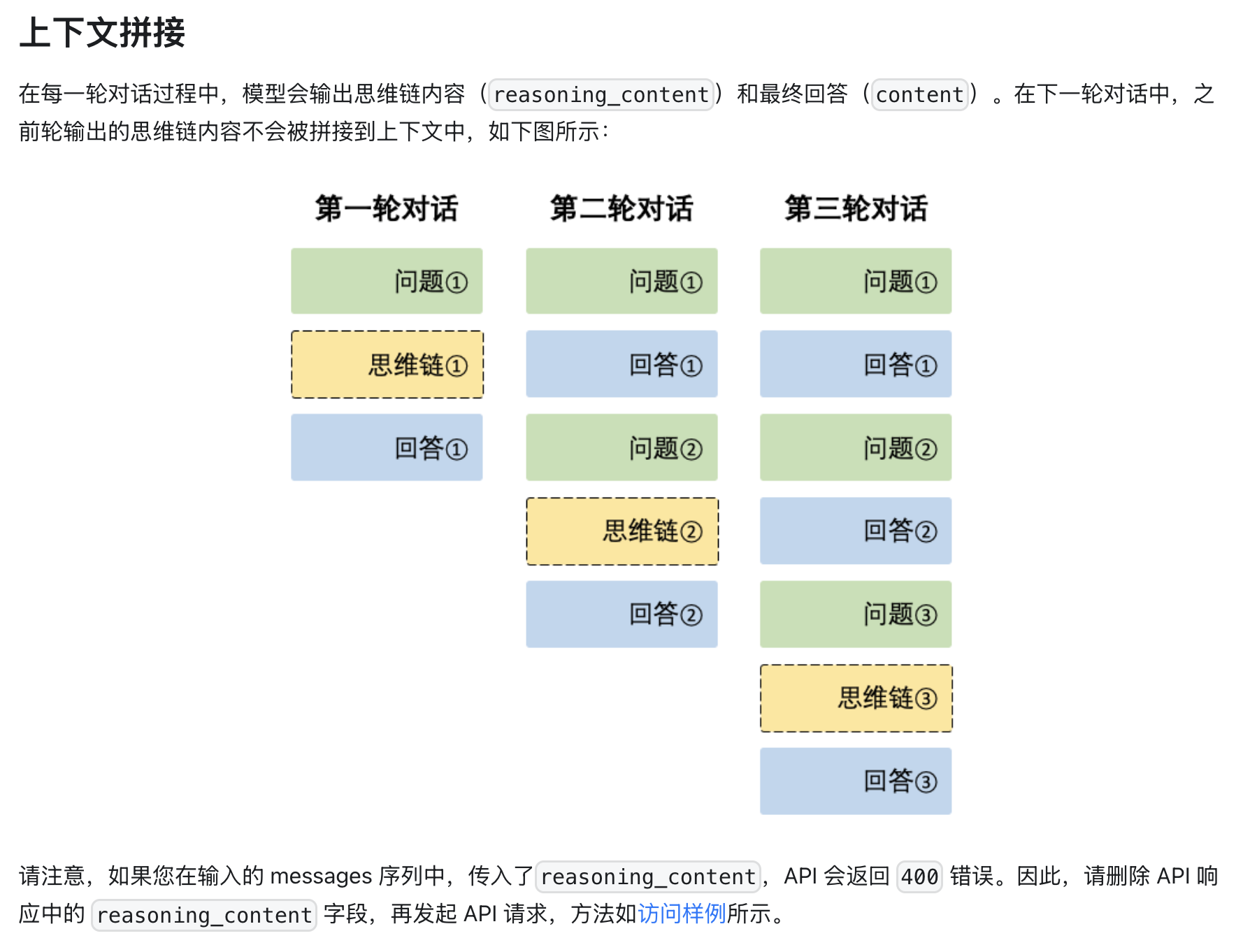
而 DeepSeek R1 则大方地提供了生成的 CoT 数据:
总之,作为用户,我不会纠结所谓 DeepSeek 套壳 OpenAI 的猜测,只希望 DeepSeek 加大力度,给大家带来更平价好用的模型。
本文转载于MSN,文章来源于知乎作者:段小草,文中观点仅代表作者本人,本站仅供信息存储