在数据分析过程中,缺失值是一个常见的问题。它们可能会影响数据的质量和分析结果的准确性。因此,处理缺失值是数据分析中的一个重要步骤。在 Python 中,Pandas 库提供了一个非常方便的函数——dropna(),用于删除包含缺失值的行或列。本文将详细介绍 dropna() 函数的作用,并通过具体的示例说明如何使用该函数来处理缺失值。
在Python中,dropna()是一个Pandas库中的函数,用于从数据框(DataFrame)中删除包含缺失值(NaN)的行或列。它用于数据清洗和预处理阶段,以便去除缺失值,使数据更加规整。
dropna()函数的语法如下:
DataFrame.dropna(axis=0, how=\'any\', thresh=None, subset=None, inplace=False)
参数说明:
axis:可选参数,表示删除行还是列。默认值为0,表示删除包含缺失值的行;设置为1表示删除包含缺失值的列。how:可选参数,表示删除的条件。默认值为’any’,表示只要存在一个缺失值就删除整行或整列;设置为’all’表示只有当整行或整列都是缺失值时才删除。thresh:可选参数,表示在删除之前需要满足的非缺失值的最小数量。如果行或列中的非缺失值数量小于等于thresh,则会被删除。subset:可选参数,用于指定要检查缺失值的特定列名或行索引。inplace:可选参数,表示是否对原始数据进行就地修改。默认值为False,表示不修改原始数据,而是返回一个新的数据框。
下面是一些使用dropna()函数的示例:
importpandasaspd#创建包含缺失值的数据框data={\'A\':[1,2,None,4],\'B\':[None,6,7,8],\'C\':[9,10,11,12]}df=pd.DataFrame(data)#删除包含缺失值的行cleaned_df=df.dropna()#删除包含缺失值的列cleaned_df=df.dropna(axis=1)#只删除整行或整列都是缺失值的行或列cleaned_df=df.dropna(how=\'all\')#至少需要2个非缺失值才保留行或列cleaned_df=df.dropna(thresh=2)#只在特定列中检查缺失值cleaned_df=df.dropna(subset=[\'A\',\'C\'])#在原始数据上进行就地修改df.dropna(inplace=True)这些示例展示了dropna()函数的不同用法,根据你的具体需求选择合适的参数设置。
附:Python丢弃含空值的行、列
创建DataFrame数据:
importnumpyasnpimportpandasaspda=np.ones((11,10))foriinrange(len(a)):a[i,:i]=np.nand=pd.DataFrame(data=a)print(d)
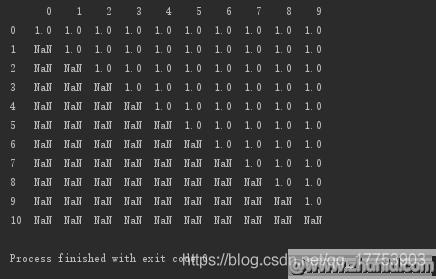
按行删除:存在空值,即删除该行
#按行删除:存在空值,即删除该行print(d.dropna(axis=0,how=\'any\'))
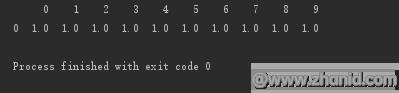
按行删除:所有数据都为空值,即删除该行
#按行删除:所有数据都为空值,即删除该行print(d.dropna(axis=0,how=\'all\'))
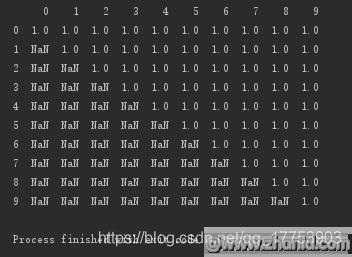
按列删除:该列非空元素小于5个的,即删除该列
#按列删除:该列非空元素小于5个的,即删除该列print(d.dropna(axis=\'columns\',thresh=5))
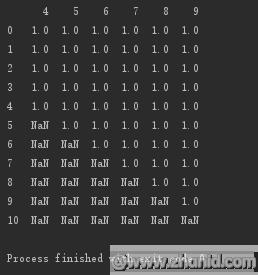
设置子集:删除第0、5、6、7列都为空的行
#设置子集:删除第0、5、6、7列都为空的行print(d.dropna(axis=\'index\',how=\'all\',subset=[0,5,6,7]))
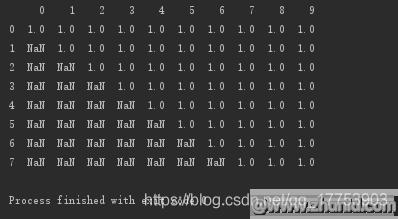
设置子集:删除第5、6、7行存在空值的列
#设置子集:删除第5、6、7行存在空值的列print(d.dropna(axis=1,how=\'any\',subset=[5,6,7]))
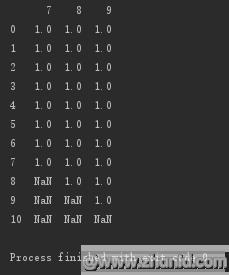
原地修改
#原地修改print(d.dropna(axis=0,how=\'any\',inplace=True))print("==============================")print(d)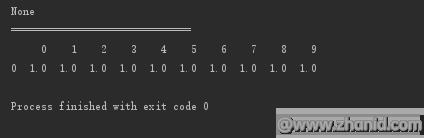
总结
本文介绍了 Python 中 dropna() 函数的作用及其使用方法。通过具体的示例,我们展示了如何使用 dropna() 函数来删除包含缺失值的行或列,以及如何自定义删除条件。dropna() 函数是一个非常实用的工具,可以帮助开发者高效地处理数据中的缺失值,提高数据的质量和分析结果的准确性。希望本文的内容能对广大开发者有所帮助,使他们在处理缺失值时更加得心应手。