这个问题要是认真聊起来,基本可以写篇小论文了。这里我就尽量捡重点言简意赅的聊聊,不过真要是不满足于当前回答,那么以下提到的每一个点,你都可以针对性查阅资料扩展了解哈!
首先必须明确一点,那就是我们聊ARM架构比x86/x64架构省电,可不是说ARM处理器那堆晶体管就比x86/x64那堆晶体管省电,也不是非得无比严谨的强调什么工艺差别,芯片设计人员的水平差异等,而是最最直观的,采用不同架构芯片的产品本身,哪一个能效更好。
产品表现
这样问题就简单很多了,已知ARM架构的MacBook Air M3电池容量为52.6瓦时,很多续航相对较好的x86/x64架构的笔记本电池容量能到99瓦时,而同样负载下前者的续航时间却可以是后者是两倍以上。所以毫无疑问,MacBook Air的能效就是更好,也就是更省电。

我知道有人可能要跺脚了,你这根本就不是纯粹比较架构的能效差异!
是的,但是这完全不妨碍得出定性的结论。更何况,开始就已经强调了,ARM的能效优势源自整个产品设计。就像苹果把内存放在芯片边上,降低延时,间接省电,你非要说这和ARM架构无关当然也没错,毕竟Intel下一代的Lunar Lake也要这么玩了!但是,现状就是现状,甚至过去很多年ARM就是这么玩的,比如iPhone采用的A系芯片。

难不成你买个钻戒,还非要一个劲的强调,钻石那堆碳原子其实不贵,贵的是钻石切割工艺和营销。那么问题来了,难不成你就此认为钻戒不贵了吗?
注意,ARM架构的能效从来不只是仅仅源自具体的CPU、GPU核心。说白了,CPU核心的能效从来都不只是核心的能效。就像Apple Silicon M系列芯片可以按需关闭快速不用的部分,省电哇!也能在需要的时候迅速开启,不影响使用。
设计导向
ARM从诞生开始,就是面向低功耗的移动端设备的,核心目标就是超低的功耗,然后才是高性能,最终演化成追求高能效。
而x86/x64就完全不同,它所追求的首要目标从来都是高性能,能耗一直都是其次。反正插电使用,反正一堆服务器都是放在机房满负荷使用。哪怕是到了今天,x86这边为了追求高性能,都可以把CPU主频提升到6.2GHz,电脑展上愣是有人超频到10GHz以上,你说这功耗能低吗?
举个简单的例子,下面的蓝色曲线是Ultra 9 185H CPU多核性能和能耗曲线,注意横轴30W~80W区间,Ultra 9 185H实际上是用提升了近50W的功耗,功耗大概提升167%,换来了41%的性能提升。你可能会说,我大不了不要那个性能了,就30W跑行不行?
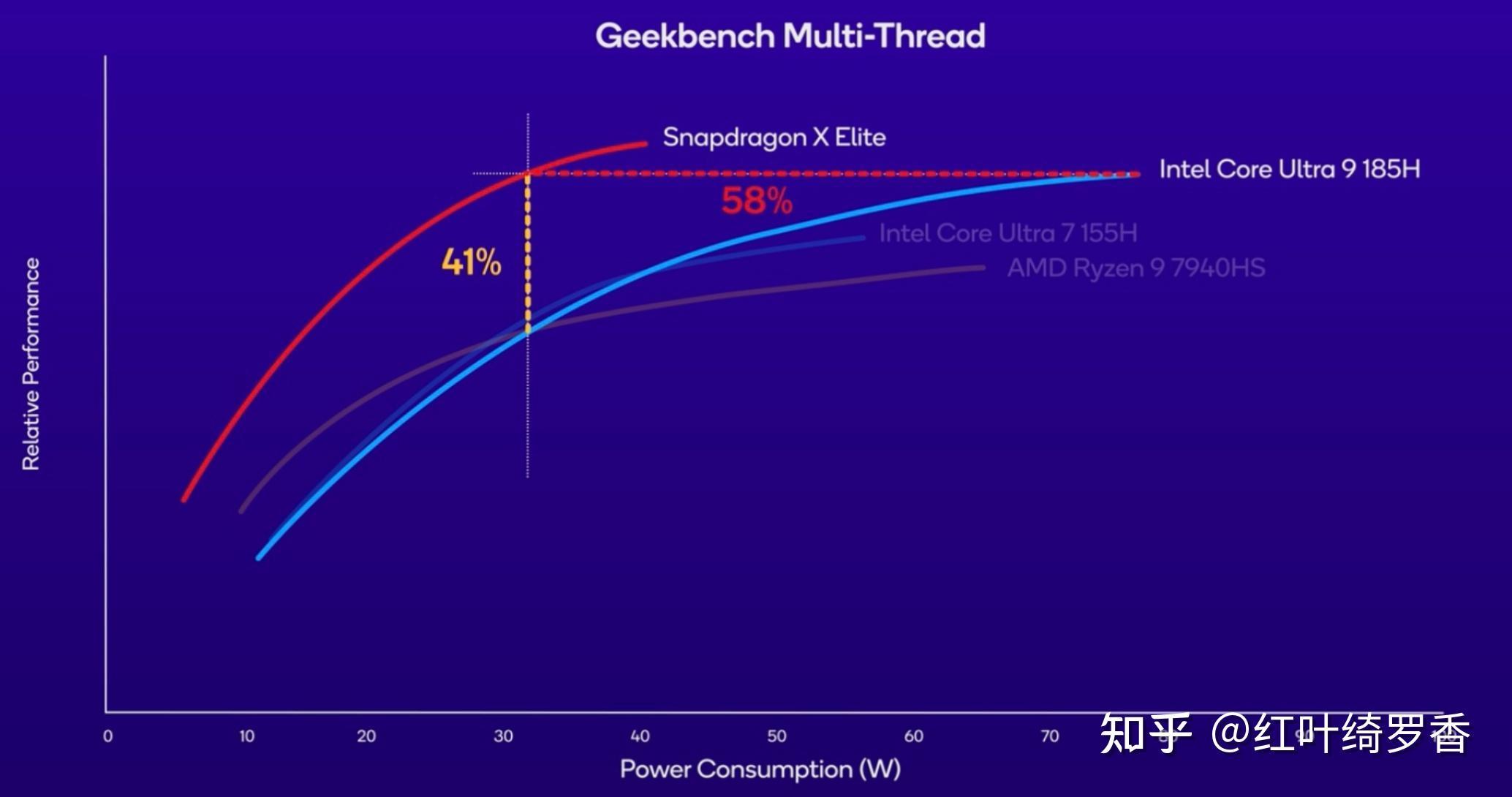
很可惜,答案是不行。一方面,没有那个峰值性能表现,一堆人压根儿不会买单。另一方面,Ultra 9 185H 30W下的性能,换ARM芯片其实只要15W不到就能达到了!
实际上,低功耗高能效的设计导向,和绝对高性能设计的导向,早就让两个阵营的设计思路完全不一样了!不同目标导向带来的演化层面的差异,是完全不可预测的,对同一个问题的解决方案也可以完全不同。
但是无论是AMD全新的ZEN 5 + ZEN 5c大小核心设计,还是Intel这边的Lunar Lake统一内存架构设计,多少都看到了一点殊途同归的意思了。

工艺影响
很多人最容易想到的因素,一般都是工艺制程。毕竟,每一个工艺节点的迭代,都对应着性能的提升和能效的提升。比较经典的Tick-Tock(工艺年-构架年)模式,说的就是因特尔处理器迭代的模式就是工艺提升应付一代,微架构提升应付一代,然后循环。其中Tick年说的就是生产工艺提升带来的性能和能效进步。
而ARM架构的芯片往往为了更极致的性能,都会优先采用成本更高的新工艺。比如A17 Pro和M3系列芯片率先采用的台积电N3B工艺,再比如M4使用的N3E工艺。

新工艺带来的能效优势肯定是有的,但是有意思的是,Intel Ultra系列处理器采用的Xe LPG架构的Arc集显,用的已经是台积电N5工艺了,而AMD Ryzen™ AI 9 HX 370用的也已经是台积电的N4工艺了,那么它们对标N5/N5P的M1/M2,有能效优势吗?
答案很简单,没有!证据吗?直接看产品单核性能和能耗,或者多核性能和能耗,基本一目了然。英特尔Arc显卡的功耗依然远高于M系列芯片,AMD的HX 370芯片的功耗也依然高于M系列芯片。
这其实就说明了,同工艺下,ARM依然有优势!
主频和IPC
其实有一个很明显的现象,很多人选购Intel或者AMD处理器的时候,特别看中那个最高主频,看到5GHz/6GHz就会莫名其妙的兴奋。
没办法,长期以来,主频就基本决定了一秒内处理器能干活的次数。你看,你M1只有3.2GHz,假设一个时钟周期只能完成一次运算,那M1在1秒就只能计算32亿次。再看i9-14900KS那可是6.2GHz,假设这玩意也是一个时钟周期完成一次运算,那人家1秒就能计算62亿次。
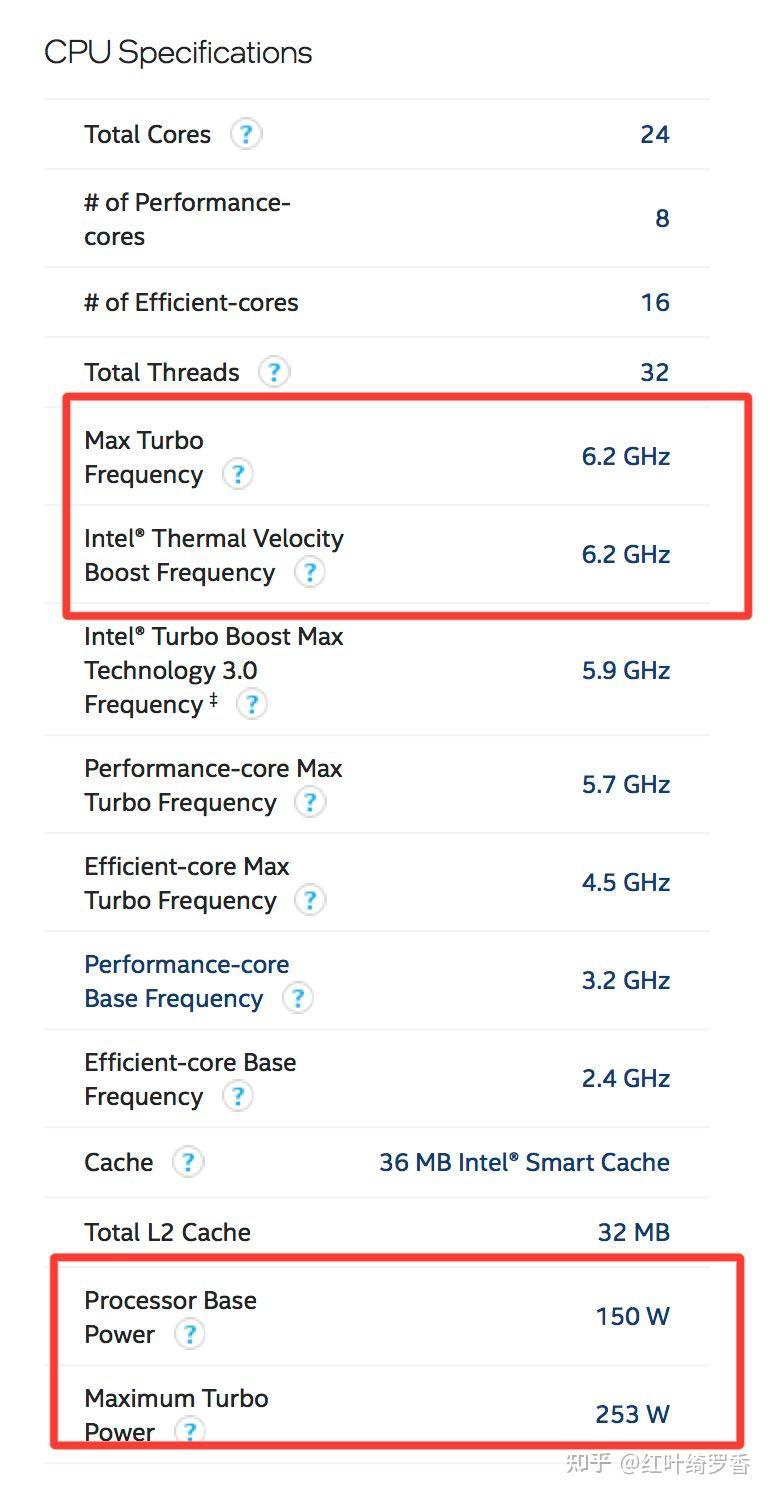
很可惜,在相同架构设计下的处理器里面,这样看问题完全没错。这也是x86处理器那么热衷于提升频率,甚至玩命超频的根本原因。
但是吧?不同架构的处理器,IPC是不一样的!这里稍微扩展讲一下处理器的IPC。
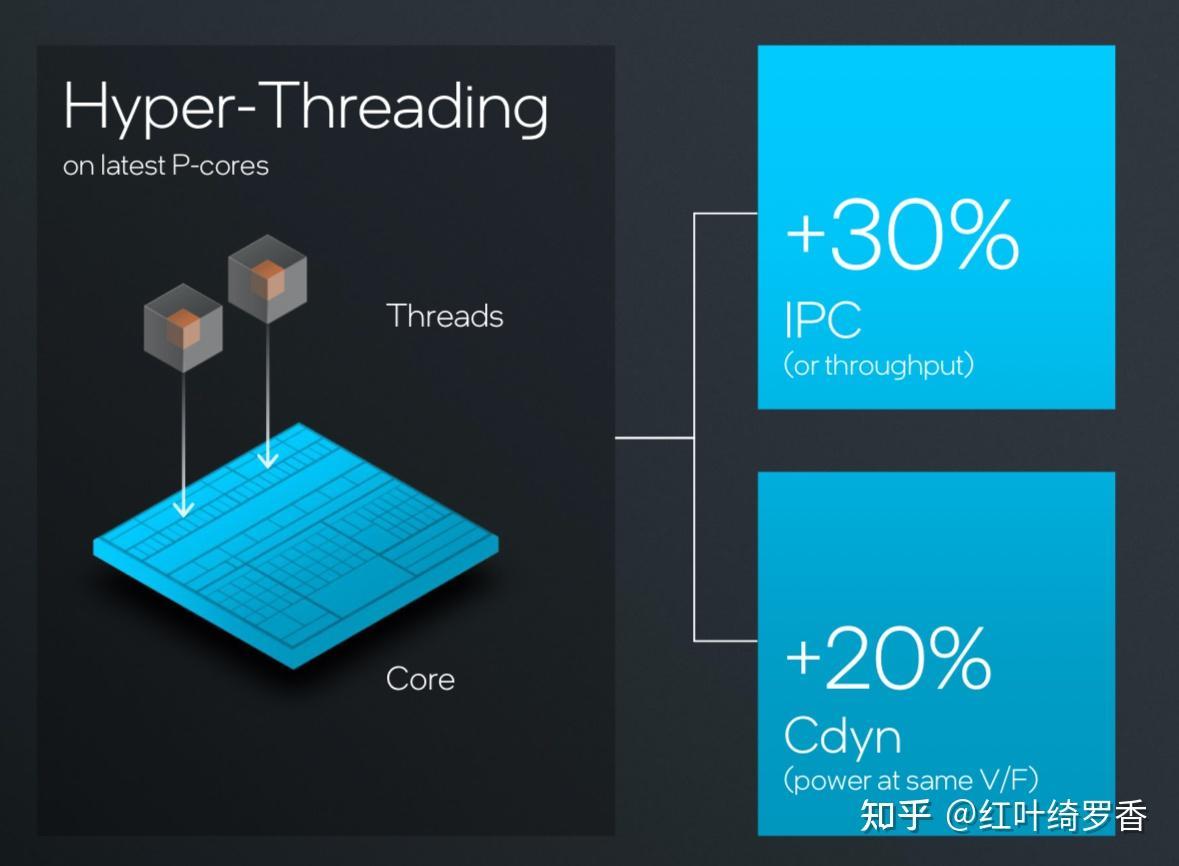
芯片所谓的IPC可以简单理解为每一个时钟周期内,处理器可以执行的指令数量,也就是Instructions Per Cycle/Clock,或者也可以简单理解为单位时钟内能做多少事情。
比如英特尔这边的i9-14900KS,主频都已经6.2GHz了,而M1才3.2GHz,如果大家IPC相同,那么二者单核性能差异就是主频的差异,也就是前者单核能有后者2倍左右的性能。
IPC体现的是一个芯片设计厂商绝对的芯片设计能力,IPC高的处理器一般有这么几个特点:缓存够大,主要是L2/L3/SLC等,专门设计用于整数、浮点和内存操作的执行引擎,超高水平的分枝预测能力,指令加载和存储的高效设计,前端指令预取和指令解码器宽度更大,重排序缓冲区设计优秀等。
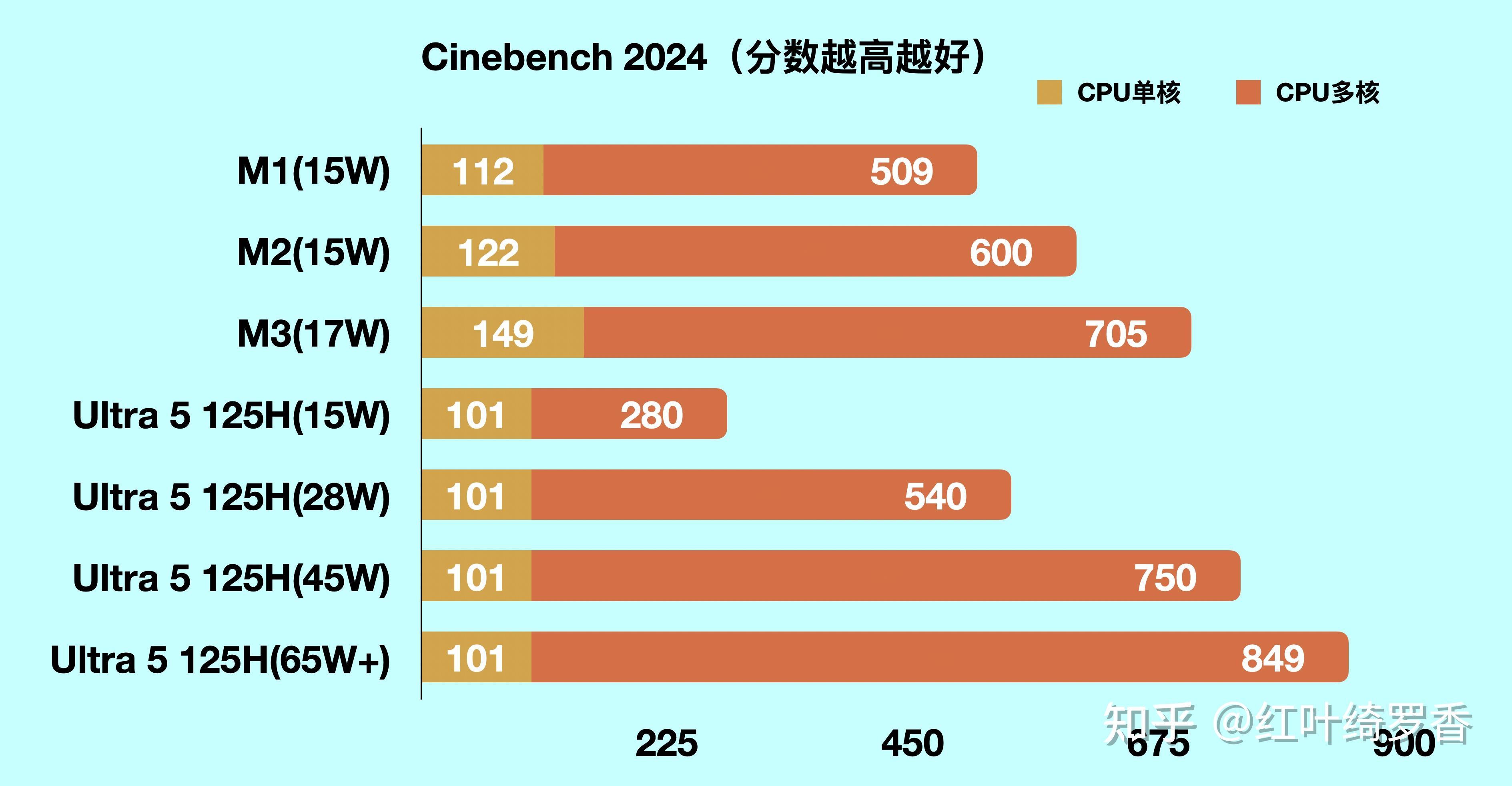
IPC比较起来也很简单,只要在相同的测试基准下,直接用性能除以主频就可以了。比如粗略估计可以利用Cinebench 2024单核成绩,在Cinebench 2024测试下,Ultra 5 125H单核101分,主频4.5GHz,而M1单核是112分,主频是3.2GHz。Ultra 5 125H的IPC为22.4,而M1为35。M1的IPC比Ultra 5 125H高了56%!

而更准确一点,可以用业界公认的SPEC2017来测算。Ultra 5 125H的P核心整数能跑到7.60,主频是4.5GHz,那么IPC就是7.60/4.5 = 1.69。而浮点能跑到12.22,主频同样是4.5GHz,那么IPC就是12.22/4.5 = 2.72。
而同样是SPEC2017,M1的主频是3.20GHz,整数跑分7.48,浮点跑分11.53,也就是说,M1的整数运算IPC为2.34,浮点运算IPC为3.60。
相较于Ultra 5 125H,M1的整数IPC高了38.5%,浮点IPC则高了32.4%。相对于每年个位数百分点都不容易的IPC增长来说,Ultra系列甚至就是零提升,你觉得这个差距还需要多久能追上呢?
很明显,无论怎么算,M1的IPC搁今天来看依然是无敌的状态。
不过这里需要强调一句,高性能情况下的高IPC才真正更有价值。否则搞个频率1.6GHz,绝对性能只有M1的一半,那么即便有着媲美M1的IPC,也没什么价值。
外围I/O功耗
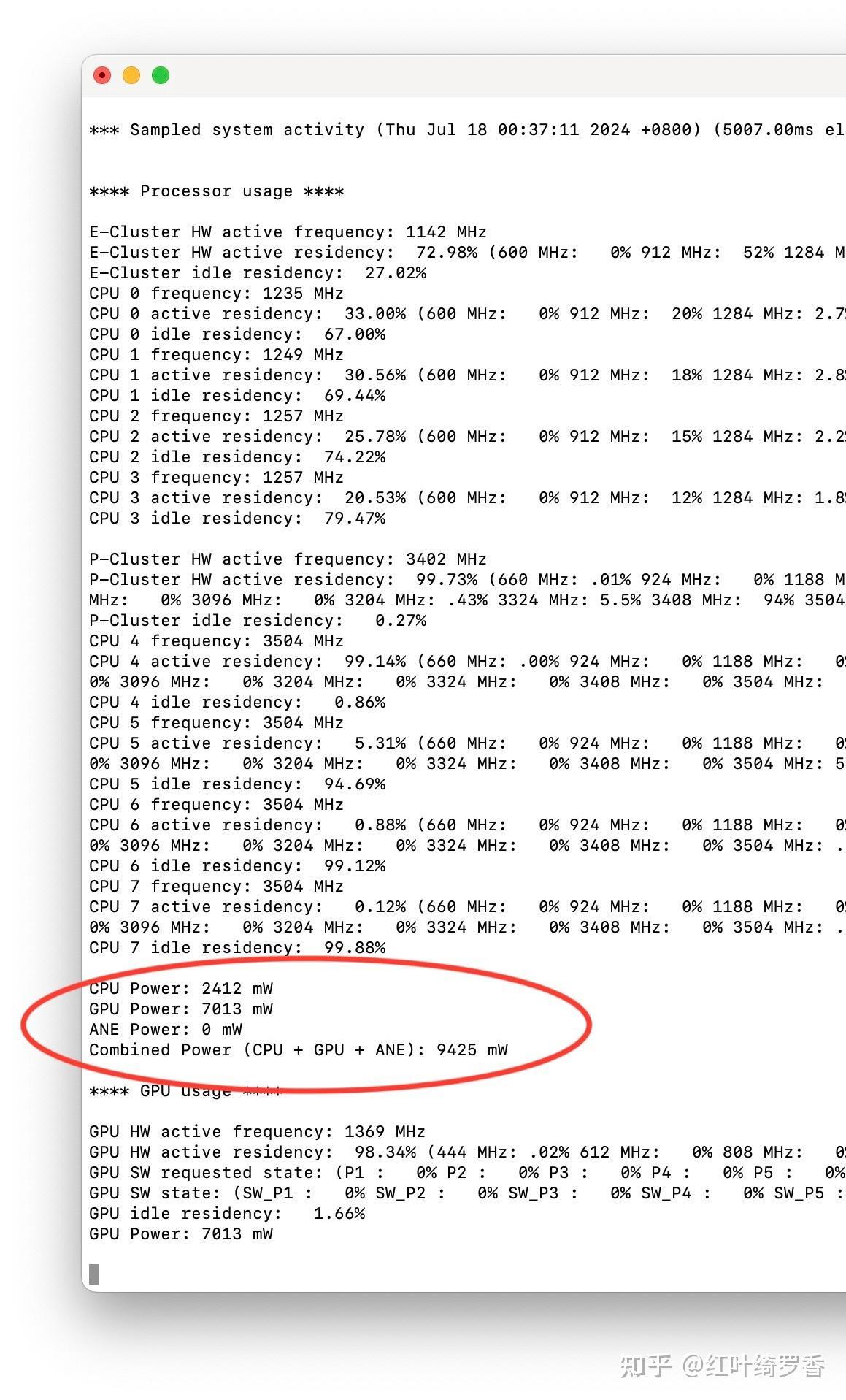
我估计很多人怎么也想不通,为什么搭载Apple Silicon M系列芯片的MacBook可以有着Windows笔记本两倍甚至三倍的续航能力,而且还是在电池容量更小的情况下做到的。这是M2 GPU高负荷运行时的功耗。
这是M2 CPU满负荷运行时的功耗。
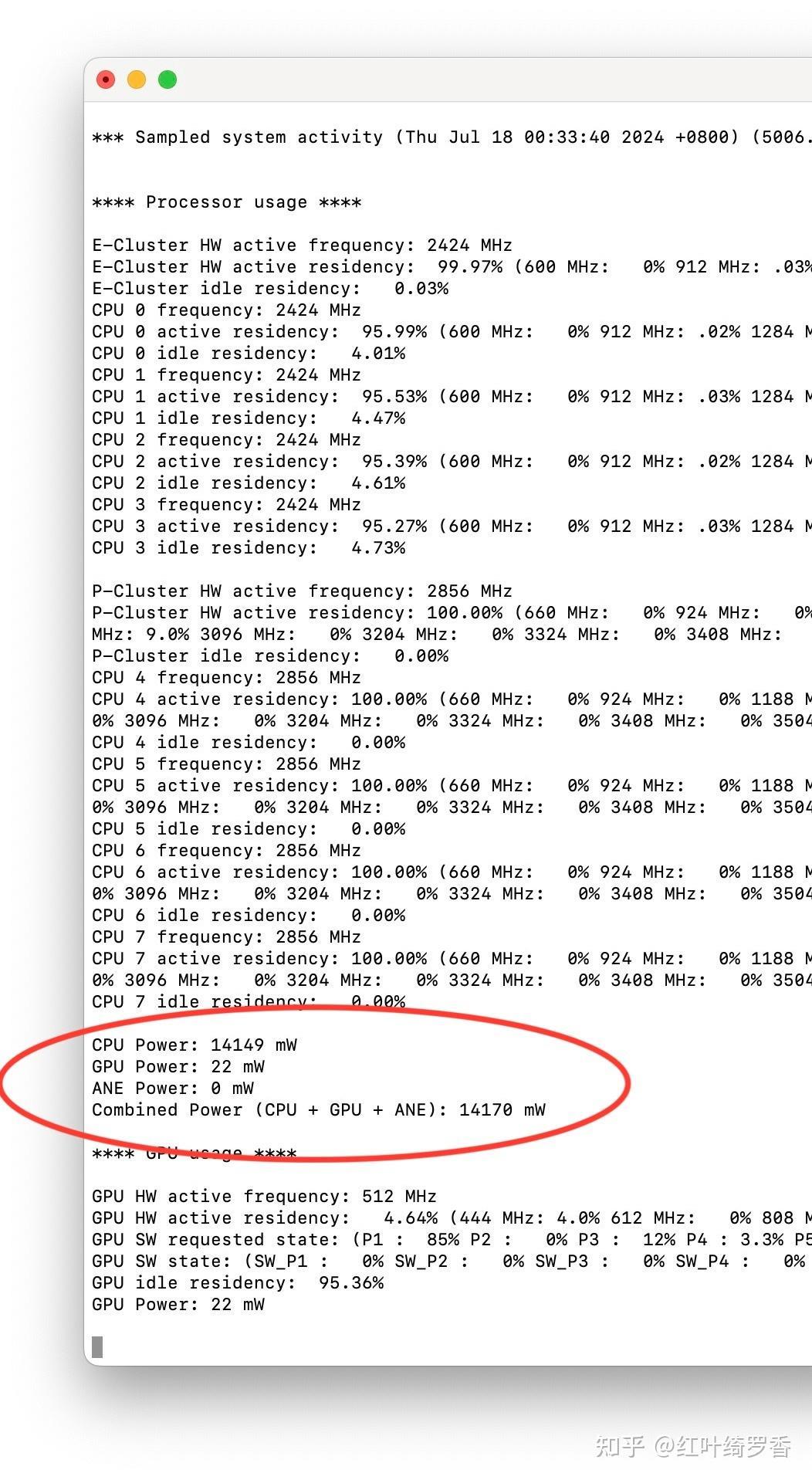
实际上,纯粹计算芯片本身的功耗是不可能得出这么大的差距的!那么原因是什么呢?
其实很简单,那就是纯粹芯片以外的功耗开销,往往比芯片本身要多得多。最容易想到的,屏幕本身能效太差,就会更耗电。过多的端口,空载功耗控制差,即便不使用也有功耗开销。再比如很多芯片喜欢堆超多的核心,而在你只用单核或者少量几个核心的情况下,另外几个核心真就是完全零功耗吗?当然不是。
某些x86处理器跑单核的时候,一样可以跑出50W的功耗,很显然,纯核心的功耗当然不可能有那么大。实际上,那些应该闲着的核心一样有不小的功耗,而内存访问的功耗往往比核心的功耗还要高!
如果你对芯片DieShot有所了解,应该就会知道,其实芯片上除了大家最关心的CPU、GPU以外,还有很多其它专用处理器。比较偏一点的,下面我用红色标出了M3 Max的LPDDR5内存控制器,绿色标出了雷电控制器,还有黄色部分的I/O。这些部分加一起,其实已经不比CPU的规模小了!

频繁访问内存可不仅仅是功耗增加,内存本身的延时也会大幅影响处理器的性能。那么问题来了,如何降低延时,提升性能,还能降低功耗呢?
我们不妨看看苹果是怎么做的。
统一内存架构
我知道很多人还在执迷于插槽内存,自己可以随时扩展当然很棒。但是即便是仅仅把插槽内存变成板载内存,都可以让内存频率提升,提升内存带宽,大幅提升CPU和GPU性能。
而统一内存架构则更进一步,直接把内存封装在处理器边上。我估计很多人可能都不相信,如今处理器的速度,已经足以感知到处理器和内存之间的距离。说的简单点就是,如果内存距离处理器稍微远一点,都可能白白浪费CPU时钟周期。

缓存规模(L2/L3/SLC)
兴许你已经发现,内存的操作都能大幅影响性能和功耗,那么要是能够减少内存访问,是不是更能从根本上提升能效呢?Bingo,你说的没错。
很多人对于L2 Cache、L3 Cache肯定不陌生,毕竟这玩意也总被处理器厂商拿出来当成卖点。不过二三级缓存对于处理器的性能提升确实有很大作用,简单来说,能在这里找到的东西,就根本不需要去内存找了啊!
而ARM芯片往往就会提供较大的二三级缓存!多说一句,你别看有些处理器也宣称有很大的二三级缓存,实际上因为核心数太多,平均到每个核心也就没有多大了。哪怕是桌面级顶级的处理器,一般也就24MB左右的缓存容量。比如AMD最新的HX 370处理器,4个ZEN 5大核心共享16MB的L3,8个ZEN 5c小核心共享8MB的L3。

为什么不堆夸张的缓存呢?因为则玩意是实实在在的晶体管堆出来的。
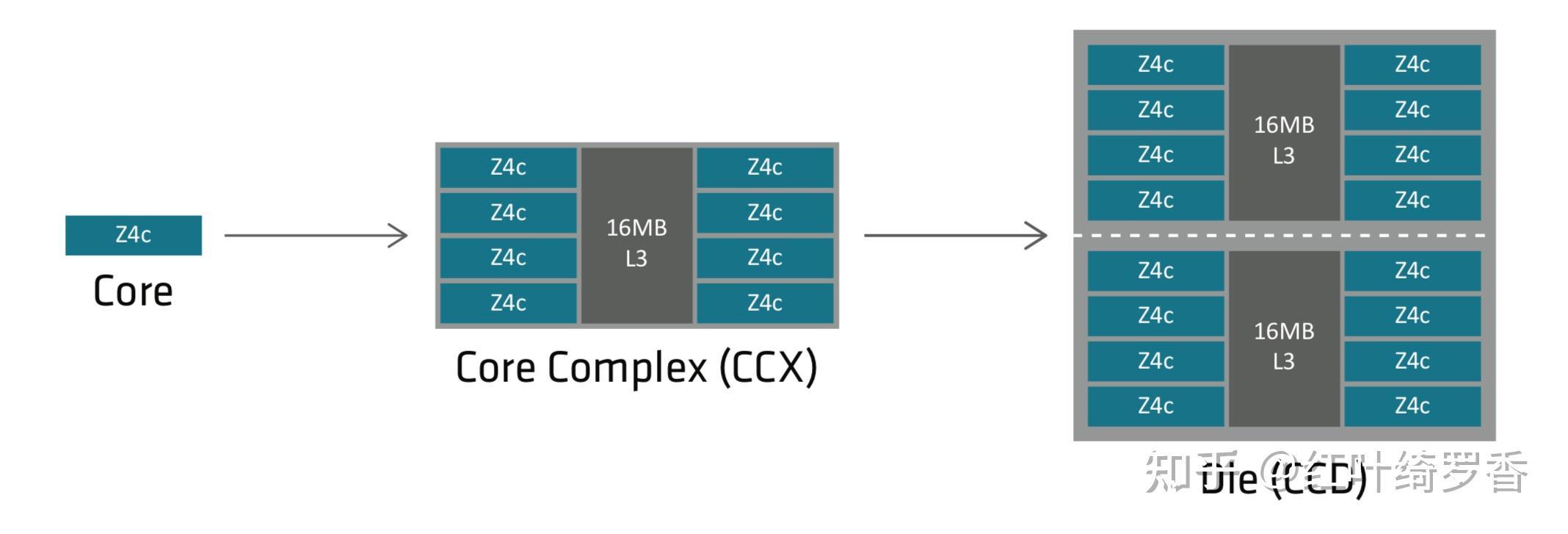
而苹果的A/M系列芯片实际上没有L3这一层,而是直接用更大的片上缓存SLC。这个规模能有多大呢?这么说吧?A/M系列芯片真就是动辄几十MB的L2缓存,注意,这里说的是L2。哪怕是A15这种手机端的芯片,苹果也曾经直接给到了32MB的SLC。我就这么说吧?这些缓存用到的晶体管,不知道比很多处理器的CPU核心多多少了。
比如下图蓝色部分就是M3 Max的SLC。

L0,L1 Cache
前面聊了这么多缓存,你是否会好奇,有L2、L3、SLC,那么有L1吗?当然有。
L1一般分两部分,数据缓存和指令缓存,我们重点聊聊后者。
指令缓存其实就是用来预取指令的,粗略的讲,你预先取的指令越多,那么后端能够尽快执行的指令就越多,也就是处理器干活越快。
那么ARM架构处理器的指令缓存一般能给到多大呢?以Apple Silicon A/M系列芯片为例,大核心一般都是192KB的指令缓存,小核心也有128KB指令缓存。而x86处理器这边给到的典型值是多少呢?32KB。你没有看错,就是只有ARM架构处理器的1/6。
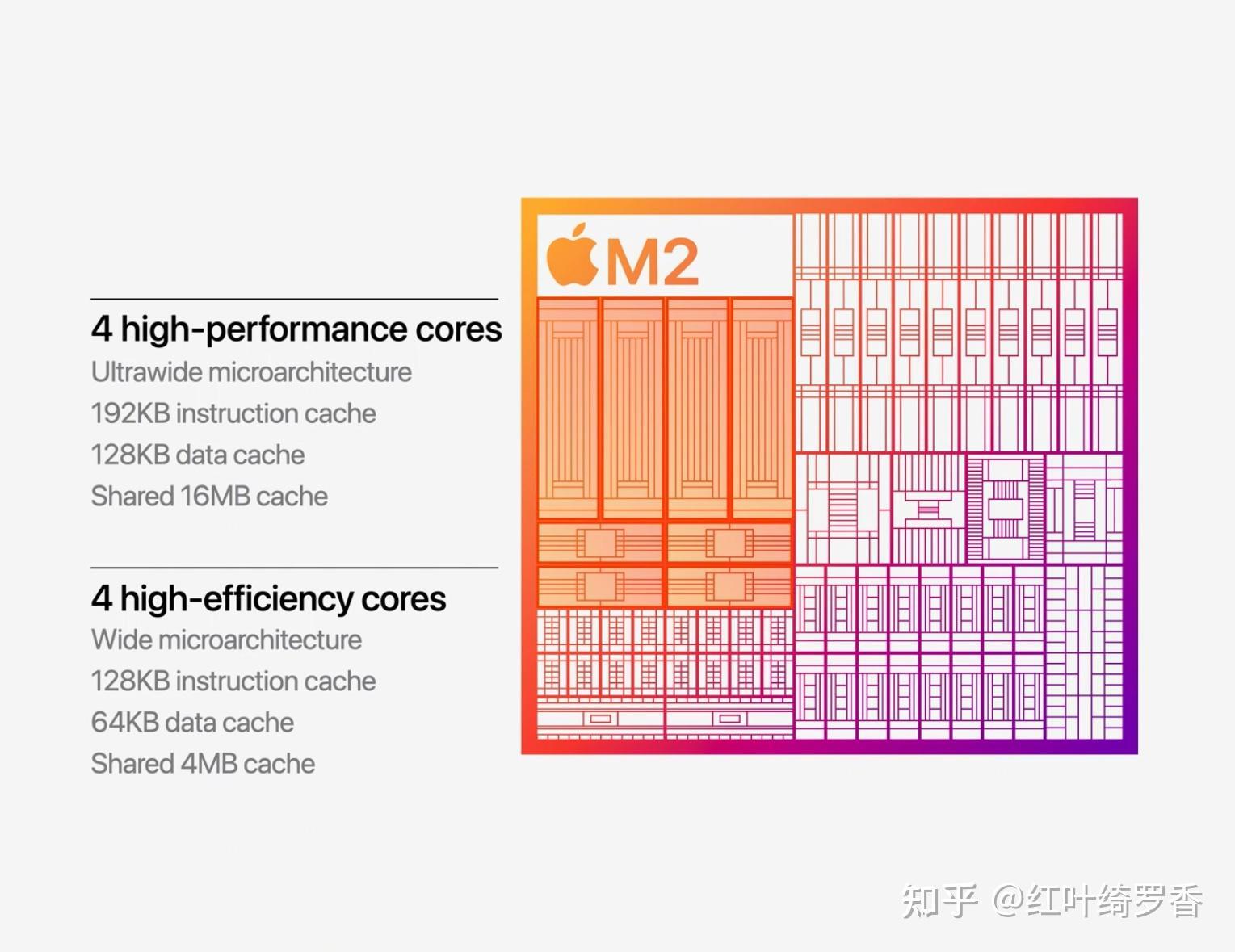
当然,Intel也已经意识到了指令缓存的重要性了。下一代的Lunar Lake,Lion Cove大核心也给到了192KB,不过Redwood Cove小核心只给了48KB。
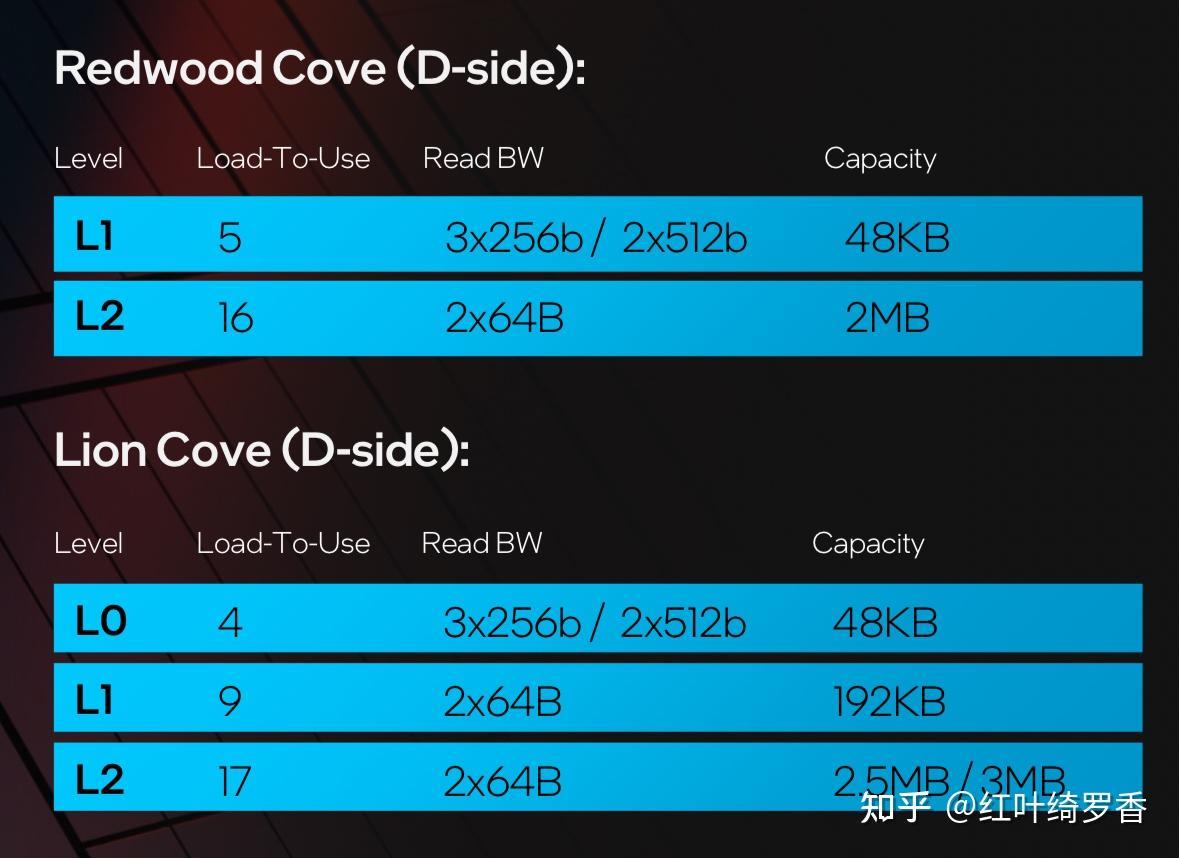
是不是还有L0呢?你还别说,通俗的讲,L0其实就是Micro-op cache,也就是微指令缓存。这玩意理论上和寄存器是一个级别的,读取延迟基本只有一两个时钟周期。这里重点聊聊ARM架构和x86/x64架构下寄存器的差异。
寄存器这玩意吧?你可以理解为代码在执行的时候,最终运算的具体数据的载体。比如你可以拿一个寄存器存储一个常数,也可以用来存储一个内存地址,也可以存储函数地址。
如果你看过反汇编代码,应该就知道,这样的代码实际上就是在来来回回倒腾这些寄存器的数据,而这基本就是处理器最底层的流水线处理了。这部分内容其实就已经涉及指令集架构ISA(Instruction Set Architecture)了,这里只是简单聊聊。
x86架构下只有8个寄存器。
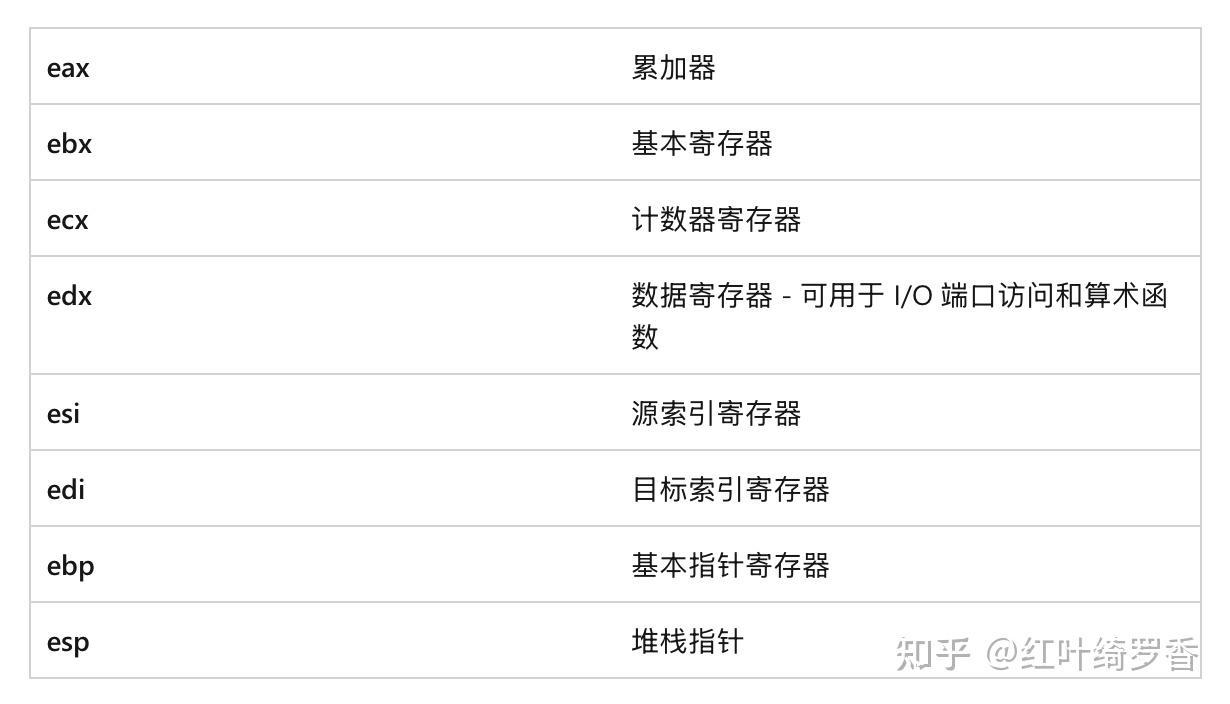
x64扩展了寄存器的位数,同时新增了8个全新的寄存器。
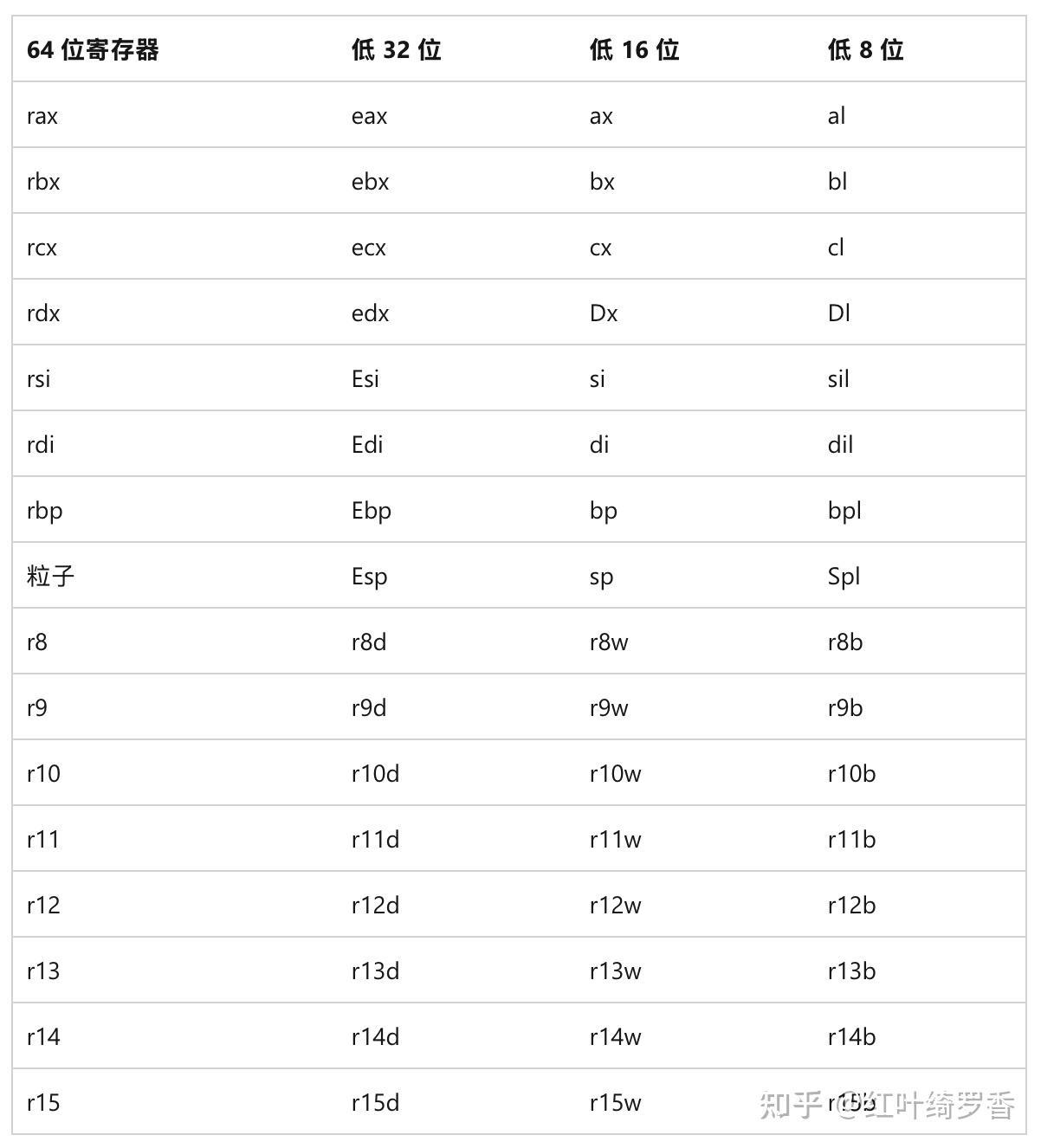
ARM64架构呢?
支持32个整数寄存器,其中提供了31个通用寄存器。
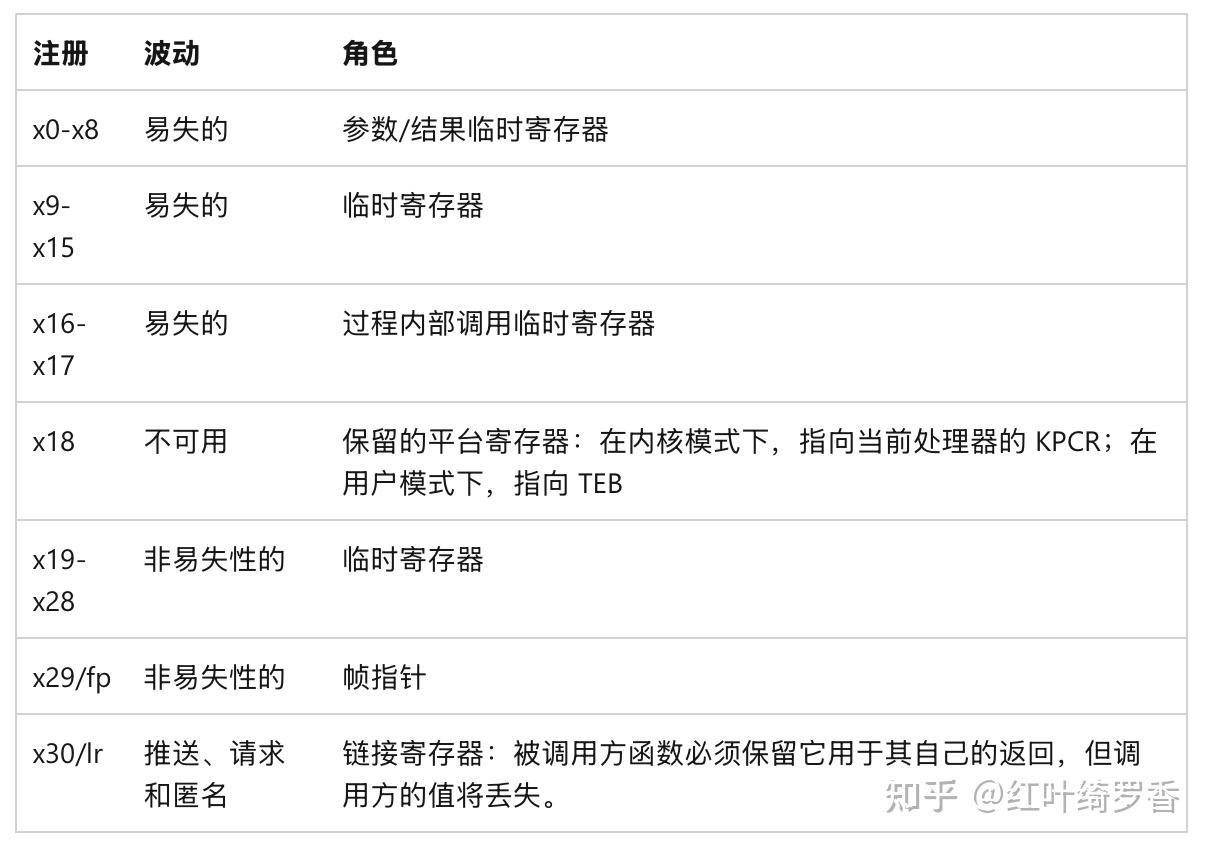
这些寄存器可以通过不同的方式访问完整位宽,或者访问其中的32位。
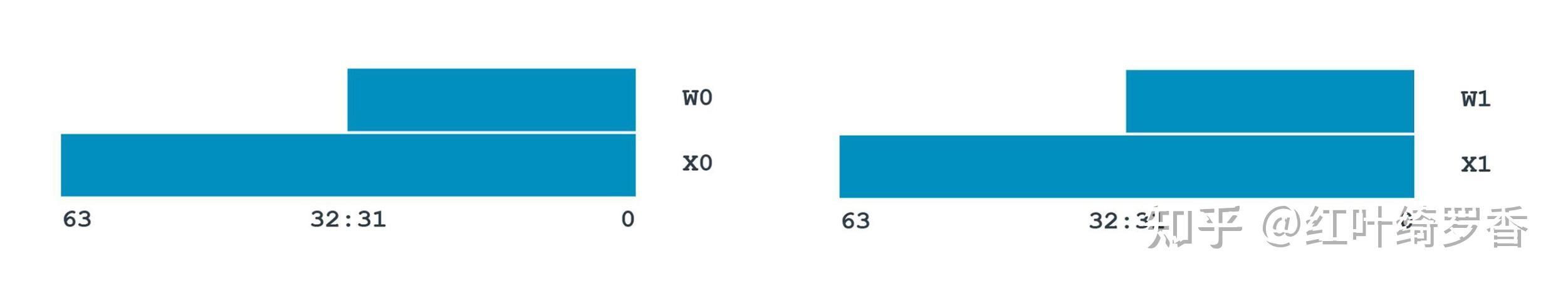
另外还支持32个浮点/SIMD 寄存器。
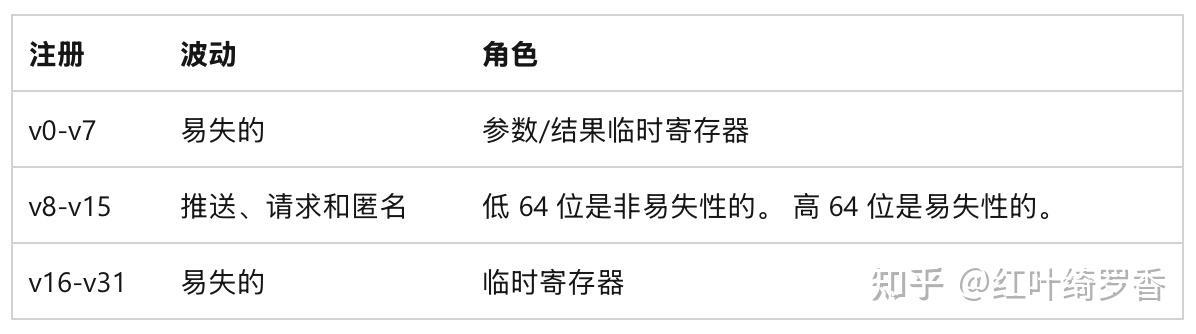
这些浮点寄存器都是128-bit的,可以通过不同的方式访问其中的一部分宽度。
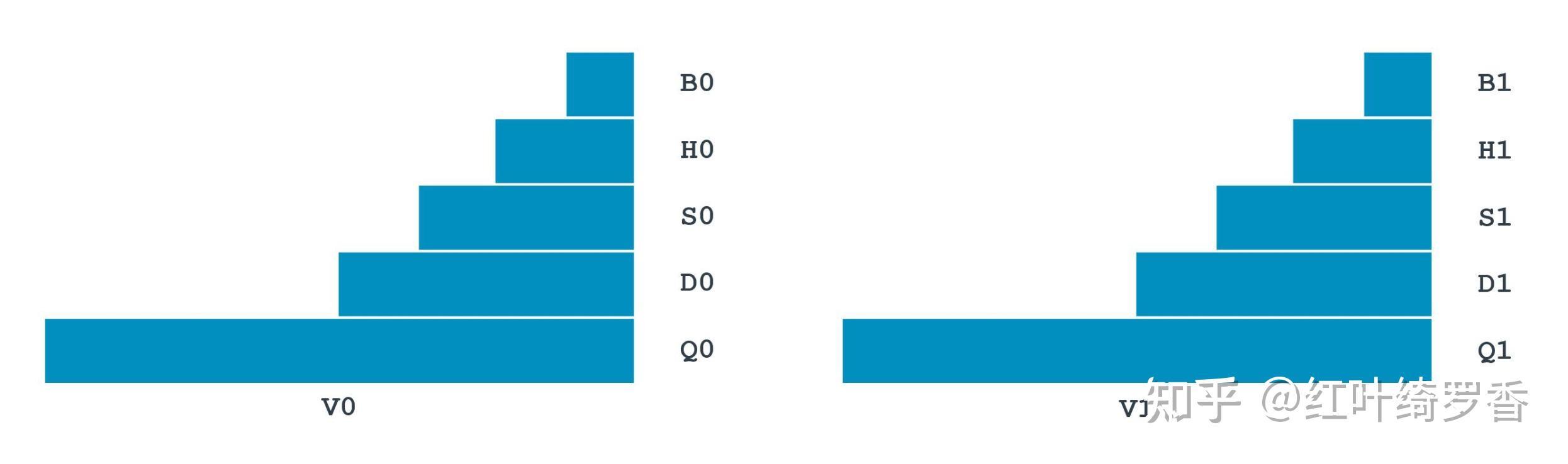
最直观的感受,其实就是ARM架构设计了丰富的寄存器,使用起来也更加方便灵活。而这本身也是出于效率的考虑!
这部分内容有空再展开深入聊聊,有兴趣可以先关注我哈! @红叶绮罗香
架构内部的执行单元
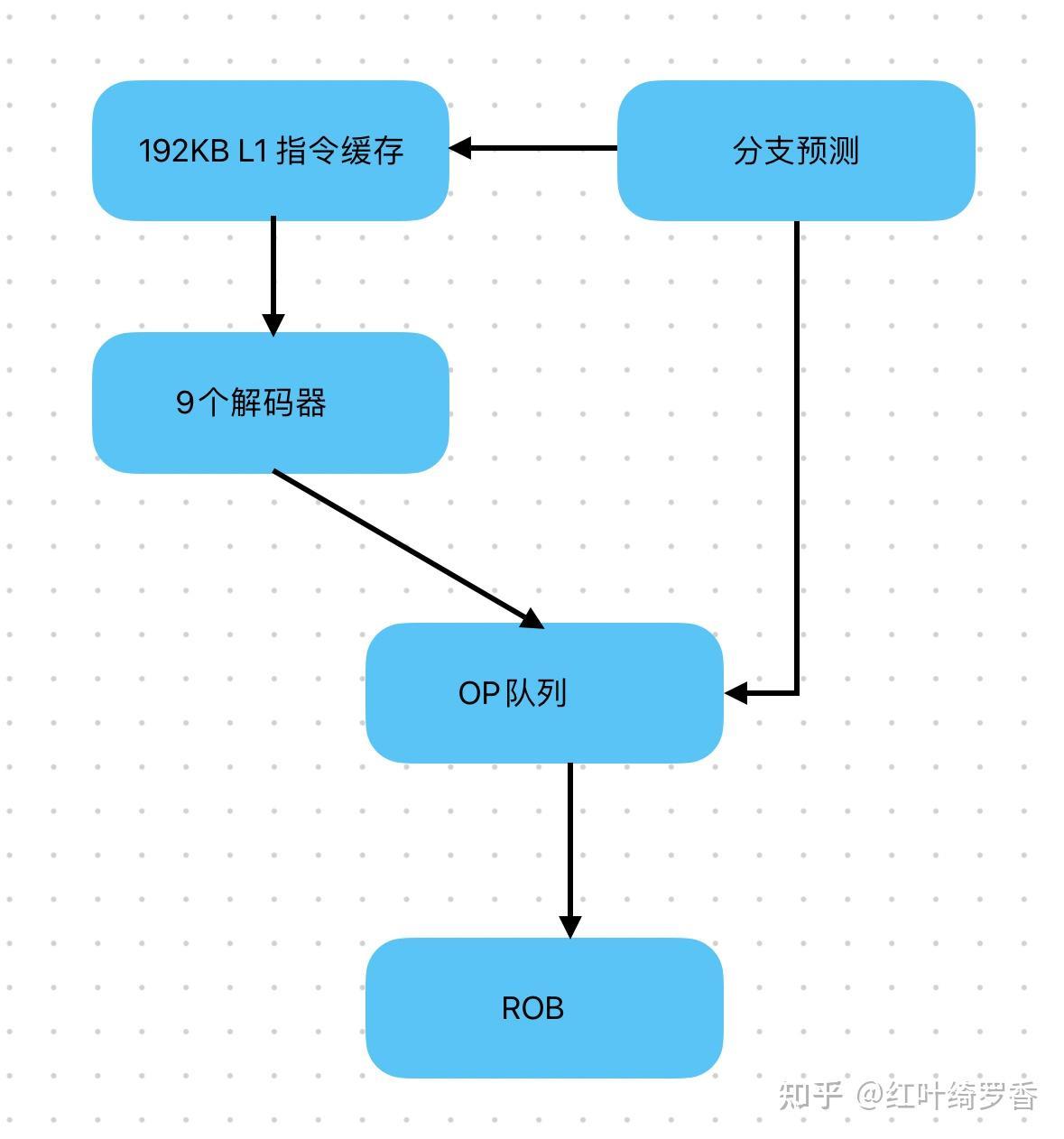
前面聊到的L1指令缓存,这里取到的指令实际上还不是CPU能够识别的机器质量,还需要解码器做一次翻译。
x86/x64这边采用的是CISC复杂指令集,这种指令本身长度不固定,有的简单,有的复杂,现代化的处理器甚至需要设计复杂解码器和简单解码器分工合作。而CISC指令到了解码器这边,可能会被翻译成多条CPU能够处理的微指令Micro Operations。
而ARM64这边呢?本来就是RISC简单指令集,虽然也需要过一遍解码器,但是解码器本身只是做简单的对齐工作,任务要比翻译CISC轻松的多。
再进一步,ARM64架构的处理器一般配备更多的解码器单元,比如苹果的A/M系列芯片早就是8个解码器单元了,M3直接增加到9个,M4更是直接变成了10个。后端发射指令的调度器基本也都是同步增加。
有意思的来了,你猜x86/x64处理器一般能有多少个解码器呢?AMD ZEN3/ZEN4都是4个,发射器也就6个。AMD最新的ZEN5,其实也就给到8个解码器和8个发射器。Intel SkyLake只给到了1个复杂指令解码器和4个简单指令解码器,即便是到了Intel下一代的Lunar Lake架构,Lion Cove大核也只有8个解码器和8个发射器。
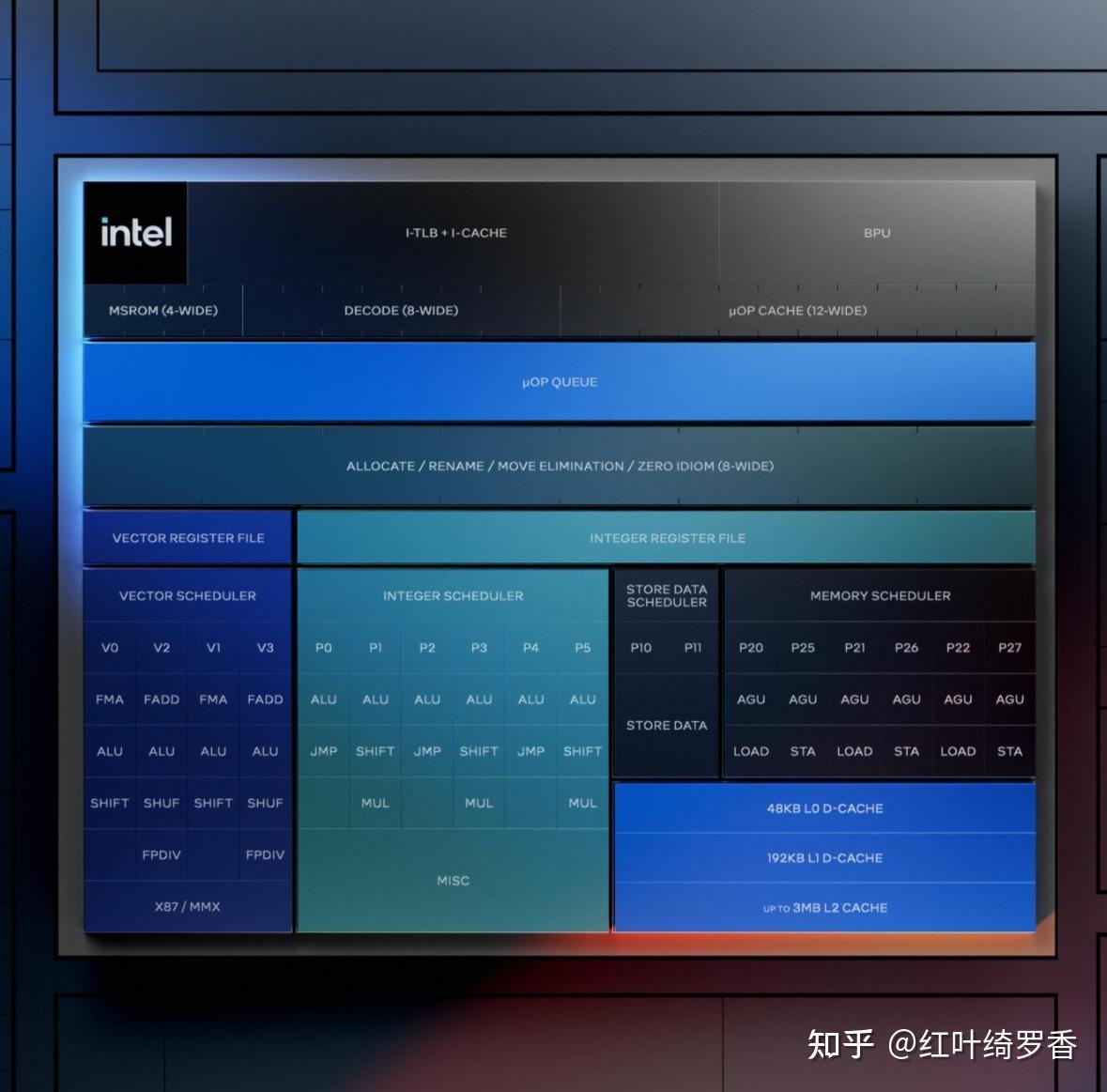
解码器的个数和效率,决定的是CPU每一个时钟周期里面,可以处理的指令个数。换句话说,只要后端没有瓶颈,那么解码器越多,时钟每跳动一次,就能执行更多的指令。
再往下,还有重排序缓冲区RoB的规模差异。比如上面提到的,Intel下一代的Lunar Lake才做到576条指令,以前无论是AMD还是Intel,一般只有200多条。而ARM架构的M1早就是630条指令的规格了。重排序缓冲区的大小,直接决定了指令并发执行的效率,太小必然就会有很多指令不得不等着前面有关联的指令执行完,白白浪费CPU周期。
前面这些说的都是指令准备,真正执行指令的执行单元ALU,无论是整数运算还是浮点运算,执行单元越多就意味着后端执行速度更快,这样前端的解码器、发射器、重排序缓冲缓冲区的规模才能真正发挥价值。而ARM架构的处理器,后端的执行单元往往也更多。

还有一个非常非常关键的因素,那就是分支预测单元,谁的分支预测设计越厉害,就可以在其他方面都相同的情况下,获得更高的性能。而基于ARM架构设计芯片的苹果,就拥有着近乎顶级的分支预测的能力。
再往后,x86/x64这边有对AVX指令的探索和实践,ARM也有SME的拓展,本质上一直都是在各自的路径上探索迭代着。
总结
围绕ARM架构设计的芯片,目前拥有极致的IPC,已经可以在较低的频率上,跑出x86/x64架构超高频率下的性能了。比如4.5GHz的M4芯片,在iPad Pro上单核性能都可以比6GHz的i9-14900K还要高23%左右。而低频本身就意味着低能耗呀!
再简单一点,ARM凭什么更省电?就凭更多的晶体管数量!比如M3 Max拥有920亿颗晶体管。
规模取胜,不服不行!
最后,近期苹果产品降价促销,活动页可领券,有兴趣不妨关注一下。
Related Answers
本站通过AI自动登载优质内容,本文来自于知乎作者:红叶绮罗香,仅代表原作者个人观点。本站旨在传播优质文章,无商业用途。如不想在本站展示可联系删除